衡量个体差异的方法有很多,后一门是求解,是学习人工智能的基础
人工智能的本质是发现事物之间的规律,然后对未来做出预测。一般的方法是建立模型并求解模型。
《线性代数》、《概率论》和《优化论》这三门数学课,前两门是建模,后门是求解,是学习人工智能的基础。
线性代数
线性代数是学习人工智能过程中的必备知识。在线性代数中,我们最熟悉的是联立方程,而线性代数的起源就是求解联立方程。只是随着研究的深入,人们发现它有更广泛的用途。
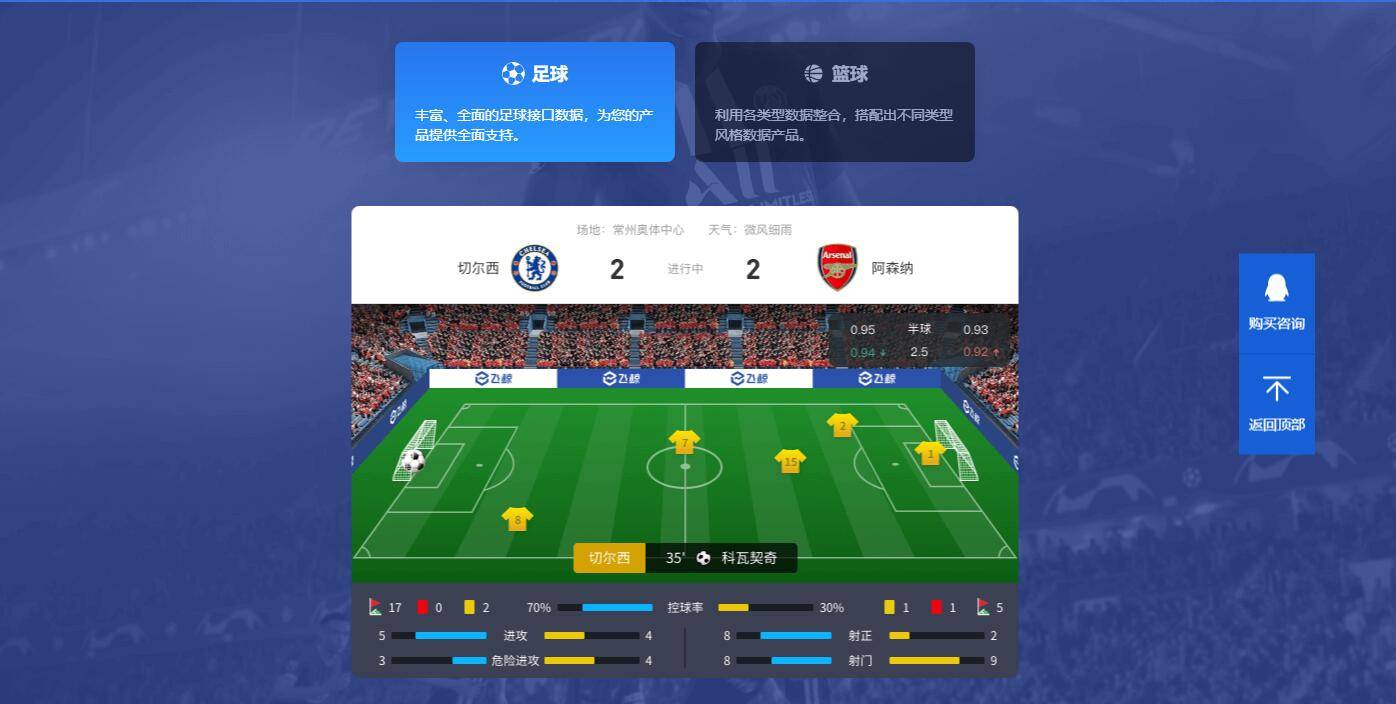
在数据科学中足球数学模型预测足球数学模型预测,通常需要知道个体之间差异的大小,然后评估个体的相似性和类别。衡量个体差异的方法有很多。有些方法是从距离的角度来衡量的。两个人的距离越近,越相似,距离越远,越不相似。有些方法是从相似度的角度来衡量的。
在用距离来衡量个体之间的差异时,最常用的距离是欧几里得距离,和我们中学学过的两点之间的距离是一样的,只不过当前点是多维空间中的一个点。
欧式距离计算公式:

对应的Python代码如下:
import numpy as np
users=['u1','u2','u3']
rating_matrix=np.array([4,3,0,0,5,0],[5,0,4,0,4,0],[4,0,5,3,4,0])
#根据公式计算用户u1和u2的距离
d1=np.sqrt(np.sum(np.square(rating_matrix[0,:]-rating_matrix[1,:])))
#计算结果
d1
5.196152422706632除了使用距离之外,相似度也可以用来衡量用户的相似度。常用的相似度是角余弦相似度。
两个向量a和b之间夹角的余弦公式:
两个向量夹角的余弦相似度可以用下面的代码计算:
def mod(vec):
#计算向量的模
x=np.sum(vec**2)
return x**5
def sim(vec1,vec2):
#计算两个向量的夹角余弦值
s=np.dot(vec1,vec2)/mod(vec1)/mod(vec2)
return s
#计算前两个用户的相似度
cos_sim=sim(rating_matrix[0],rating_matrix[1])
#计算结果为
0.749268649265355夹角的余弦越接近1,越相似。
Python中的很多工具包已经实现了大部分的距离和相似度计算,可以直接调用。
向量运算、矩阵运算、向量空间模型、多项式回归、岭回归、Lasso回归、矩阵分解等都属于线性代数的范畴。
除了使用数学公式之外,您还可以使用概率进行建模。
概率论
《概率与统计》是统计学习中的一门重要基础课,因为机器学习经常要处理交易中的不确定性。
最大似然思想是频率学派使用的概率建模思想的基础,它是根据最大似然原理提出的。
最大似然原理本质上就是以下两点:
当用概率思维对数据进行建模时,通常假设数据是从某个分布中随机抽取的,例如正态分布。但是我们不知道这个正态分布是什么样子的,均值和方差参数未知,“模型已经确定,参数未知”。这时可以利用最大似然的思想进行建模,最终得到模型参数的估计。
简而言之,最大似然估计的目标是找到一组参数,使模型生成观测数据的概率最大化。
此外,贝叶斯方法和抽样方法也可以用来估计参数。
当人们研究事件的统计规律时,他们使用随机变量来量化随机现象。如果两个随机变量不独立,可以得到著名的贝叶斯公式:
贝叶斯公式之所以很重要,是因为机器学习内置的模型可以表示为 P(H\D)。D 代表您拥有的数据,而 H 代表对隐藏在数据中的模型所做的假设。根据贝叶斯公式:
贝叶斯公式在形式上看似很简单,计算起来并不复杂,但却是贝叶斯学派的法宝。它成功地引入了先验知识并改进了频率最大似然估计方法。
这位行业领袖曾这样评价贝叶斯建模方法:“人工智能领域出现了三个最重要的进步:深度神经网络、贝叶斯概率图模型和统计学习理论。”

朴素贝叶斯的一个成熟应用是垃圾邮件分类问题。网上有很多案例,大家可以借鉴。
优化
模型建立后,如何求解模型属于优化的范畴。优化是在无法获得问题的解析解时找到最优解。当然,什么是最优的需要提前定义,就像足球比赛之前必须定义游戏规则一样。
通常的做法是想办法构造一个损失函数,然后找到损失函数的最小值来求解。
除了逻辑回归算法和凸优化之外,梯度下降算法是最经典的求解算法。
————
以上数学知识是入门级人工智能领域必知的数学知识。只有打好基础,才能建成“上层建筑”。
参考:《人工智能基础——数学知识》,作者:张晓明。
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读




猜你喜欢
-
五爱高级中学“90后”数学探究活动《体育中的数学》
2022-04-23